
Przepływ danych procesu
Parametry wejściowe i rezultaty
Patrząc na proces jak na czarną skrzynkę definiujemy, jakie dane są konieczne do jego uruchomienia i jakie rezultaty są produkowane przez proces. Innymi słowy traktujemy proces jako funkcję specyfikując jego parametry wejściowe i wyjściowe.
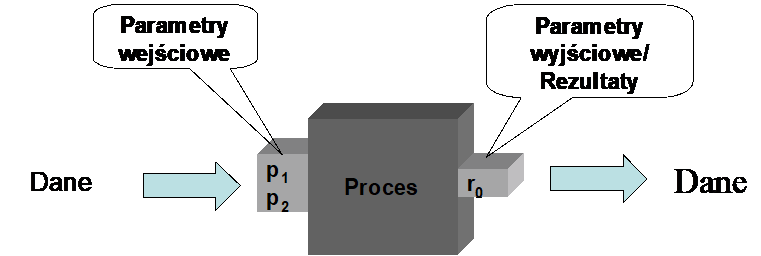
Rysunek 1. Proces widziany jako czarna skrzynka
Takie podejście jest szczególnie pożądane w przypadku, gdy dany proces jest wywoływany przez inny proces (jako podproces) lub gdy uruchomienie procesu jest wykonywane przy pomocy interfejsów programowych.
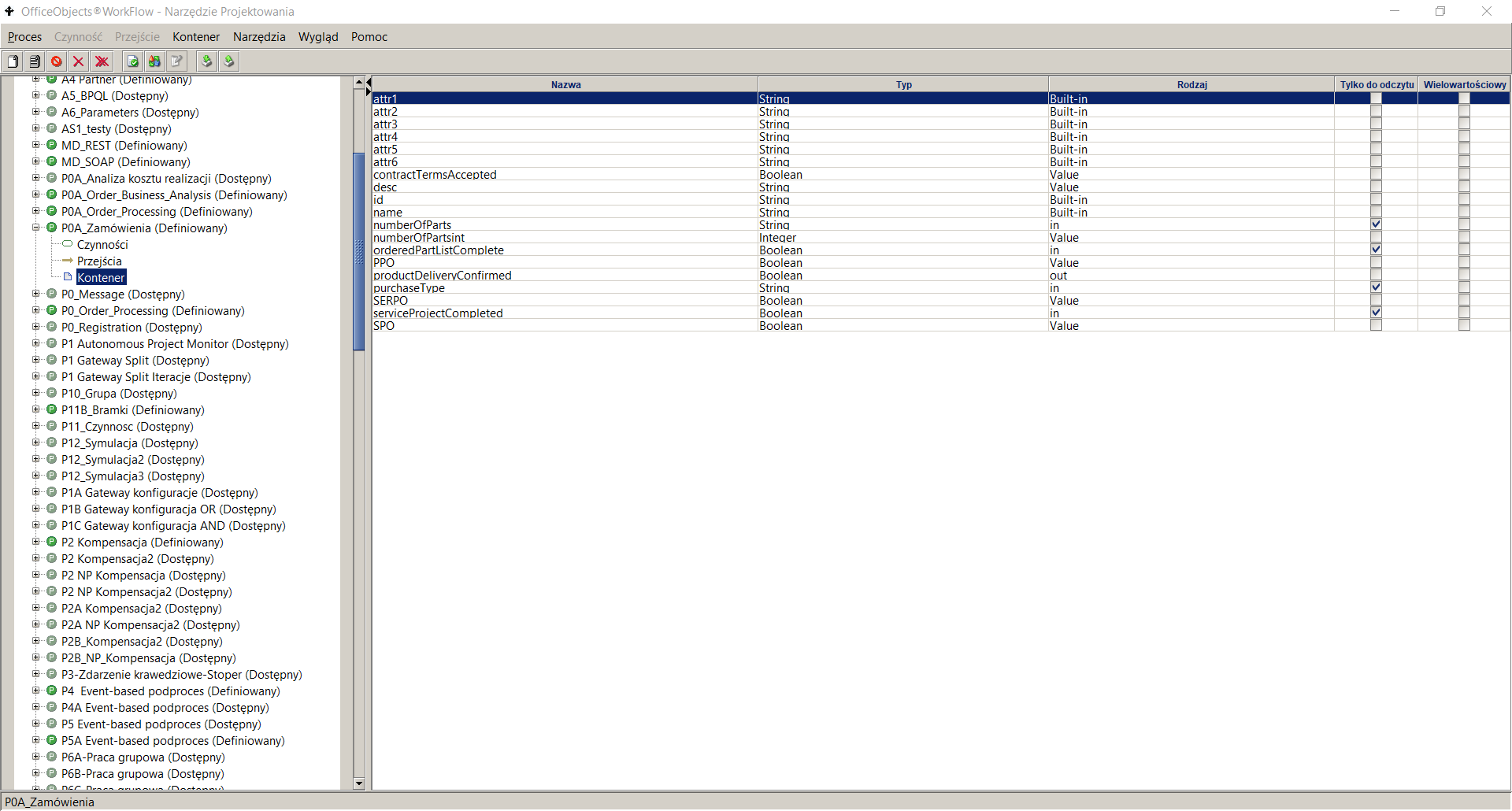
Rysunek 2. Atrybuty kontenera procesu
Aby zdefiniować nowy parametr wejściowy lub wyjściowy procesu w narzędziu projektowania procesów, należy:
- przejść na dany proces znajdujący się w panelu listy definicji procesów
- przejść na węzeł Kontener, w prawym panelu zostanie wyświetlona lista aktualnie zdefiniowanych atrybutów kontenera procesu
- Wybrać pozycję menu Kontener->Dodaj
- Wprowadzić dane o parametrze, w tym:
- Nazwa – podać unikalną nazwę. Zasadniczo jako nazwę podaje się ciąg znaków alfanumerycznych rozpoczynających się małą literą. Każdy nowy wyraz jest dołączany do istniejących i zaczyna się od dużej litery. W nazwie atrybutu nie zaleca się stosować polskich znaków diakrytycznych. Przykłady nazw: imieWnioskujacego, kwotaDelegacji.
- Rodzaj – dla parametru wejściowego należy wybrać wartość in. Dla parametru wyjściowego – wartość out. W przypadku gdy dany parametr wejściowy jest wykorzystany także jako parametr wyjściowy (rezultat), należy ustawić Rodzaj na in/out.
- Tylko do odczytu – wskazuje, że dany parametr będzie wykorzystywany tylko do odczytywania danych a w momencie próby zapisy wystąpi błąd. W przypadku parametru wejściowego parametr ten jest on automatycznie ustawiany na Tylko do odczytu. W przypadku parametru wyjściowego parametr ten powinien pozostać odznaczony.
- Typ -typ atrybutu, należy wybrać właściwy typ z listy dostępnych typów.
- Wielowartościowy – jeżeli parametr przyjmuje wiele wartości, to należy zaznaczyć to pole,
- Obowiązkowy – jeżeli zawsze jest wymagana wartość atrybutu, to należy zaznaczyć to pole. Z praktycznego punktu widzenia opcja ta ma sens jedynie przy parametrach wejściowych bo najczęściej wartość parametru wyjściowego nie jest znana przy rozpoczęciu procesu.
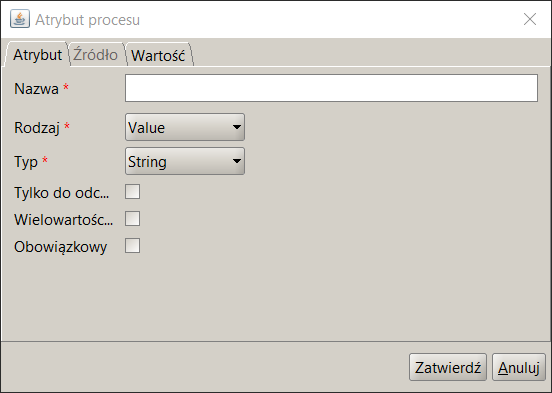
Rysunek 3. Dodanie atrybutu procesu
Atrybut kontenera danych jest zmienną globalną (ang. global variable) procesu wykorzystywaną do zapisywania tymczasowych wartości podczas wykonania procesu, wykonywania złożonych mapowań danych w procesie lub zapisywania wskaźników wykonywanego procesu.
Każdy atrybut ma określoną nazwę, typ, rodzaj oraz liczność. Dodatkowo, do standardowych atrybutów, atrybut kontenera zawiera dwa dodatkowe pola refreshable i retrieveExpr. Opis tych pól prezentuje Tabela 1.
| Nazwa atrybutu | Opis atrybutu |
|---|---|
| refreshable | Określa czy wartość atrybutu musi być wyliczona ponownie w momencie kiedy jest odczytywana. Jeżeli atrybut jest ustawiony na true, wartość atrybutu kontenera danych jest przeliczany według retrieveExpr. W przeciwnym wypadku wartość atrybutu jest bezpośrednio pobierana. |
| retrieveExpr | Wyrażenie, wyznaczające jak odzyskać wartość atrybutu. |
Tabela 1. Specyfikacja atrybutu kontenera danych procesu
W wyrażeniach BPQL można wykorzystywać zmienne procesu zapisane w kontenerze danych. Zmienne na poziomie procesu są wykorzystywane do przechowywania danych sterujących lub przetwarzanych przez proces. Aby wykorzystać zmienną w wyrażeniu BPQL, należy podać jej nazwę poprzedzoną znakiem „$”.
$<nazwa_zmiennej>
W przypadku, gdy zmienna globalna jest wielowartościowa, odwołanie do jej n-tego elementu można zrealizować przy pomocy funkcji GetMultiValueAttribute
W niektórych procesach nie ma potrzeby definiowania parametrów wejściowych i wyjściowych. Dotyczy to w szczególności procesów, gdzie parametry wejściowe są de facto wprowadzane w pierwszej czynności, najczęściej przy użyciu formularza. W takim wypadku te dane są definiowane jako zmienne globalne a nie jako parametry wejściowe lub wyjściowe.
W celu poprawienia ergonomii możliwe jest dynamiczne dodawanie parametrów wejściowych, wyjściowych oraz zmiennych globalnych w dowolnym polu akceptującym wyrażenie BPQL (pre, post-akcja, wykonawca, właściciel instancji, wartość parametru aplikacji itp.). W tym celu należy wpisać poprawną nazwę parametru bądź zmiennej, zaznaczyć ją i wybrać opcję 'Dodaj' dostępną po kliknięciu prawym przyciskiem myszy.
Dane wewnątrz procesu
Parametry wejściowe procesu są przekazywane do poszczególnych czynności. Ponieważ w czynnościach tych wywoływane są aplikacje, parametry wejściowe procesu mapowane są na parametry wejściowe aplikacji. Przykładowo, tak jak prezentuje Rysunek 4, w czynności A parametr wejściowy procesu p1 mapuje się na parametr wejściowy a1 aplikacji A1. Jako rezultat wykonania czynności A zwracany jest rezultat z wykonania aplikacji A1. Rezultat ten powinien być użyty jako parametr wejściowy a3 aplikacji A2 wykonywanej w czynności B. Aby to zrealizować, potrzebny jest obiekt wewnątrz procesu przechowujący wartość rezultatu zwróconego przez aplikację A1. Do tego celu służą zmienne globalne (opisane w poniższej sekcji). W naszym przykładzie mamy zmienną globalną v1. Zmienna ta jest użyta do wykonania mapowania na parametr wejściowy a3.. Po wykonaniu czynności B jej rezultat zapisywany jest w zmiennej v2. Ta zmienna z kolei jest wykorzystywana jako parametr wejściowy do aplikacji A3 wywoływanej w czynności C. Ostatecznie rezultat czynności C jest mapowany na rezultat procesu r1.
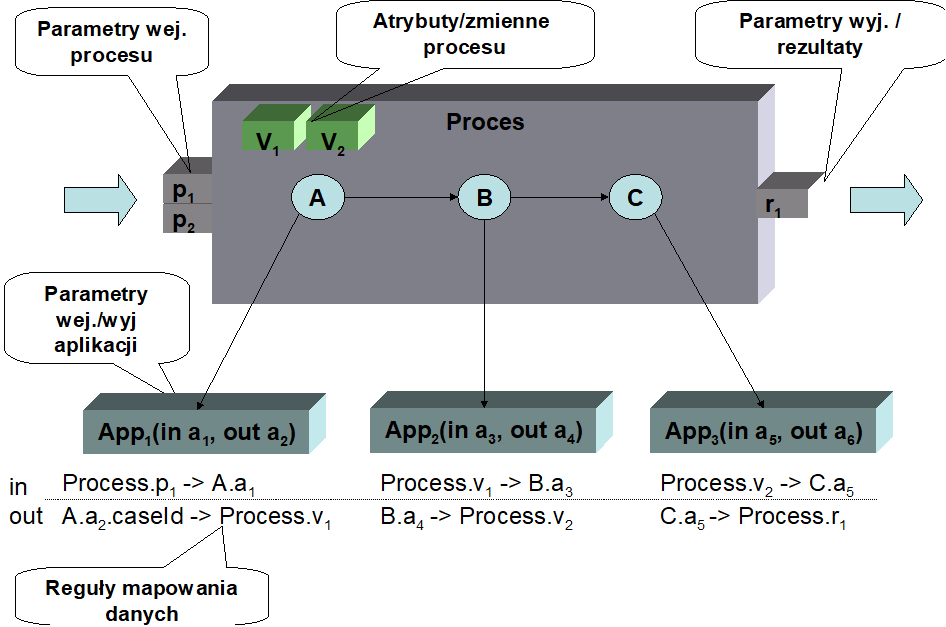
Rysunek 4. Przepływ danych wewnątrz procesu
Podsumowując, z podanego przykładu wynika, że:
- danymi wejściowymi do definiowania przepływu danych są parametry wejściowe procesu
- rezultaty procesu są umieszczane w parametrach wyjściowych procesu
- aplikacje wykonywane w czynnościach potrzebują danych wejściowych. Dane te są podawane w oparciu o parametry wejściowe procesu albo rezultaty aplikacji wykonywanych w ramach poprzednich czynności.
- aplikacje produkują rezultaty. Rezultaty te są wykorzystywane jako parametry wejściowe aplikacji wykonywanych w innych czynnościach, albo zwracane jako rezultaty wykonania procesu.
- Do zapewnienia właściwego przepływu danych pomiędzy wykonywanymi czynnościami wykorzystuje się zmienne globalne procesu.
Reguły przepływu danych są definiowane na poziomie parametrów wywoływanych aplikacji. W przypadku parametru wejściowego można określić jaka wartość zostanie podstawiona pod ten atrybut. Wyrażenie może być dowolną regułą w BPQL. W przypadku parametrów wyjściowych można zdefiniować, do jakiej zmiennej zostanie przekazana wartość rezultatu.
Zmienne globalne
Zmienne globalne mogą tez być użyte w celu „dopasowywania” rezultatów jednej aplikacji do parametrów wejściowych drugiej aplikacji. Przykładowo, jeżeli aplikacja A generuje dwa rezultaty: imię i nazwisko kontrolera jakości, a aplikacja B wymaga nazwy kontrolera (imię + nazwisko), to w zmiennej globalnej można przechować tekst będący złączeniem obu zwróconych rezultatów i w takiej postaci przekazać to do drugiej aplikacji.
Jak wskazano wcześniej, zmienna globalna procesu może być postrzegana jako tymczasowy „pojemnik” przechowujący wartości pośrednie, potrzebne w procesie do zapewnienia właściwego przepływu danych. Zmienna globalna jest definiowana w ramach kontenera procesu. Dostęp do zmiennej globalnej w dowolnej regule BPQL jest bardzo prosty, poprzez $<nazwa_zmiennej>. Jest to identyczny sposób jak dla parametrów wejściowych i wyjściowych. Przykładowo, aby zapisać do zmiennej globalnej *$*nazwaDelegowanego imię plus kropka plus nazwisko delegowanego wystarczy wykonać poniższą instrukcję:
$nazwaDelegowanego:= $imieDelegowanego + ' '+$nazwiskoDelegowanego;
Dla zmiennej globalnej określa się następujące parametry:
Nazwa – unikalna nazwa zmiennej na poziomie procesu. Zasadniczo jako nazwę podaje się ciąg znaków alfanumerycznych rozpoczynających się małą literą. Każdy nowy wyraz jest dołączany do istniejących i zaczyna się od dużej litery. W nazwie atrybutu nie zaleca się stosować polskich znaków diakrytycznych. Przykłady nazw: nazwaWnioskujacego, ryczalt.
Rodzaj – tutaj jest kilka możliwości: zmienne wbudowane (ang. builtin), zmienne zapisywane w strukturze danych systemu docuRob®WorkFlow (ang. value) i zmienne zapisywane w zewnętrznych systemach a jedynie wskazywane w systemie docuRob®WorkFlow (ang. reference). Poszczególne typy są omówione w poszczególnych podsekcjach.
Tylko do odczytu – jeżeli dany parametr będzie wykorzystywany tylko do odczytu, należy ustawić ten parametr. Dotyczy to zmiennych rodzaju value o znanej wartości początkowej, które są wykorzystywane w procesie jak stałe. Ustawianie wartości domyślnej (początkowej) wykonuje się w oknie Dodawania atrybutu procesu, na zakładce Wartość**.**
Rysunek 5. Definiowanie wartości domyślnej zmiennej procesu
Wartość domyślną mogą także przyjmować zmienne o typie Document (dokument XML). Dzięki temu można utworzyć szablon dokumentu XML, do które potem zostaną dodane poszczególne węzły. Innym wykorzystaniem tej opcji może być zapisywanie w zmiennych długich nazw pojęć z ontologii.
Typ -typ atrybutu należy wybrać właściwy typ z listy dostępnych typów. Wybór typu można wykonać dla zmiennych rodzaju value i reference. Dopuszczalne są następujące typy proste:
- String – dowolny ciąg tekstowy. Ciąg tekstowy może zawierać dowolne znaki ujęte w znaki apostrofów. Przykłady: 'alabama', 'ala bama', 'Części zamienne', 'Część nr #234',
- Integer – wartość całkowita. Przykłady: -123, 345, 0,
- Double – wartość rzeczywista. Znakiem oddzielenia części całkowitej od ułamkowej jest znak „.” Przykłady: 123.56, -23.67,
- Timestamp – data i czas. W przypadku wprowadzania stałych możliwe jest podawanie tylko dat. Dopuszczalne formaty dat to: YYYY-MM-DD oraz YY-MM-DD (gdzie: Y- cyfra roku, M- cyfra miesiąca, D- cyfra dnia). Przykłady: 2001-01-01', '2008-07-23',
- Boolean -wartość logiczna. Dopuszczalne wartości to: true (prawda) oraz false (fałsz), ważna wielkość liter),
Oprócz typów prostych dostępne są też trzy typy złożone:
- Binary – reprezentuje plik nieinterpretowany przez system docuRob®WorkFlow. Może to być plik dowolnego formatu, który jest, w ramach procesu, przekazywany pomiędzy czynnościami.
-
Document – kompletny dokument (plik) XML, który może być interpretowany przez reguły dostępne w BPQL.
-
Node – fragment dokumentu XML (także plik) reprezentujący wierzchołek XML, który może być interpretowany przez reguły dostępne w BPQL.
Wielowartościowy – jeżeli parametr przyjmuje wiele wartości, to należy zaznaczyć to pole, Dodawanie kolejnych wartości może być wykonywane przy pomocy interfejsów programowych. Zastosowanie tych zmiennych jest opisane w kolejnej podsekcji,
Obowiązkowy – jeżeli zawsze jest wymagana wartość atrybutu, to należy zaznaczyć to pole. Z praktycznego punktu widzenia opcja ta ma sens jedynie przy zmiennych o wartości początkowej.
-
Zmienne wbudowane
Zmienne wbudowane to ograniczony zestaw specjalnych zmiennych wbudowanych w model danych systemu docuRob®WorkFlow. Ze względu na takie ich zlokalizowanie dostęp do nich jest szybki. Zmienne te wykorzystuje się przede wszystkim do przechowywania informacji, która:
- identyfikuje zewnętrzne dane związane z procesem (np. identyfikator dokumentu, identyfikator sprawy),
- przechowuje dane wyświetlane na liście zadań dotyczące obsługiwanych obiektów, np. numer korespondencji, nazwa dokumentu, itp. Dane te mogą być sortowane razem z podstawowymi danymi dotyczącymi zadania takimi jak nazwa zadania, wykonawca, data realizacji, itp.
Zakłada się, że atrybuty wbudowane otrzymują wartość na początku procesu i potem ich wartość się nie zmienia. W szczególności jest to kluczowe, gdy atrybuty te przechowują identyfikatory do obiektów zewnętrznych lub numery pojawiające się na liście zadań. Dodatkowo, są to atrybuty tekstowe. Jeżeli przechowamy w nich wartości numeryczne, to sortowanie może być inne niż wymagane (konieczne uzupełnianie miejsc znaczących z przodu liczby spacjami). Zmienne te można wykorzystać do tworzenia nazw i opisów czynności.
Aktualnie w systemie istnieje dziewięć wbudowanych atrybutów tekstowych:
- name – zaleca się wykorzystanie tej zmiennej do przechowania nazwy, sygnatury lub numeru obiektu (korzenia obiektów) przetwarzanego w procesie
- id - zaleca się wykorzystanie tej zmiennej do przechowania identyfikatora obiektu (korzenia obiektów) przetwarzanego w procesie
- desc - zaleca się wykorzystanie tej zmiennej do przechowania opisu obiektu (korzenia obiektów) przetwarzanego w procesie.
- attr1, attr2, attr3, attr4, attr5, attr6 – sześć atrybutów o dowolnej interpretacji.
Zmienne rodzaju value
Zmienne te są zapisywane w rozszerzalnych strukturach procesów. Dostęp do nich nie jest tak szybki ale i tak nie wymagają każdorazowego odczytu z zewnętrznego systemu jak to jest wykonywane w przypadku zmiennych wskaźnikowych. Z drugiej strony zmienne te mogą być wielowartościowe i przyjmować dowolny typ prosty jak i złożony.
Zmienne wskaźnikowe
Zmienne te są najbardziej elastyczne gdyż umożliwiają odczyt danych zapisanych w zewnętrznym systemie. Ze względu na źródło danych wyróżnia się dwie możliwości:
- baza danych – system jest w stanie odczytać dane z bazy danych. Zakłada się, że dane te są dostępne do odczytu dla użytkownika systemowego (potrzebne odpowiednie widoki). Odczyt następuje przez protokół JDBC. W celu odczytania informacji, narzędzie projektowania potrzebuje następujących danych:
- nazwa kolumny- nazwa kolumny, z której zostanie odczytana wartość zmiennej,
- nazwa tabeli – nazwa tabeli, gdzie ta kolumna się znajduje,
- warunek – warunek wyszukania rekordu we wspomnianej tabeli. Najczęściej w warunku używa się kryterium selekcji związanej z identyfikatorem obiektu przetwarzanego w procesie zapisanego w zmiennej wbudowanej $id.
Zmienne wielowartościowe
Zmienne wielowartościowe umożliwiają obsługę sytuacji gdzie ze względu na wielorodność ścieżek w procesie występują różne wartości tych samych danych. Przykładem jest opinia podejmowana przez kilku pracowników (jedna czynność, ale wiele instancji tej czynności) – wiele opinii jednostkowych.
Poszczególne wartości w zmiennej wielowartościowej są identyfikowane poprze klucz. Kluczem może być kolejna liczba całkowita, ale może być także identyfikator instancji czynności, w której zapisano wartość. Zarówno w czynności A jak i w czynności C zapisujemy wartość zmiennej „cost*.* Wartość zmiennej jest zapisywana przez API interfejsów programowych.
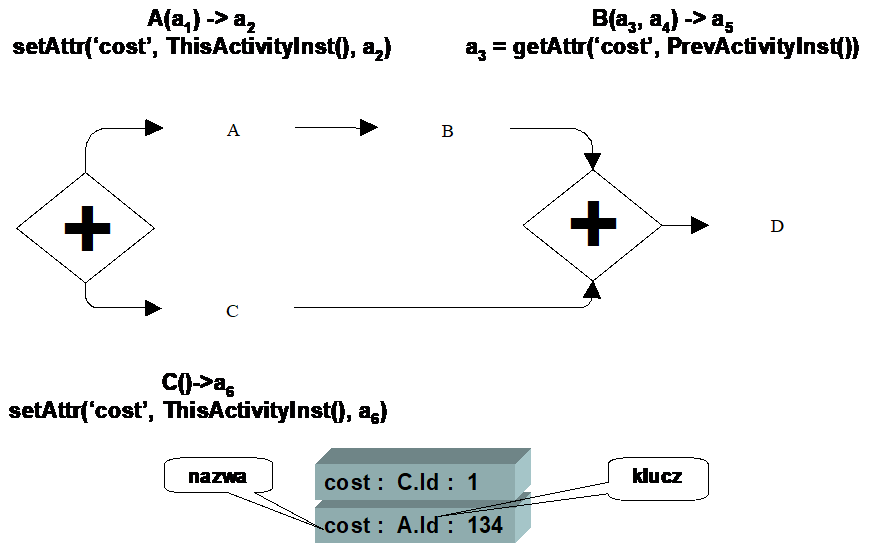
Rysunek 6. Zastosowanie atrybutu wielowartościowego
Ponieważ ścieżki, gdzie są zlokalizowane czynność A i czynność C są wykonywane równolegle, wymagane jest zapisanie danych dotyczących kosztu jako dwie wartości. Załóżmy, że w czynności B chcemy odwołać się do wartości zapisanej w czynności A. Aby to uzyskać, potrzebujemy właściwych kluczy. Zastosowanie prostego indeksu nie sprawdza się, ponieważ dalej nie wiadomo, która wartość została zapisana w czynności A.
Innym sposobem jest wykorzystanie jako klucza identyfikatora instancji czynności. W takim podejściu odczyt wartości zapisanej w czynności A jest prosty: w czynności B odwołujemy się przy pomocy funkcji BPQL służącej do odczytania identyfikatora poprzedniej instancji czynności i ten identyfikator przekazujemy jako klucz do odczytu wartości kosztu.
Zmienne lokalne
Oprócz zmiennych globalnych zdefiniowanych dla danego procesu i dostępnych w każdym jego miejscu, istnieją zmienne lokalne dostępne w ramach poszczególnych czynności. Ponieważ zmienne te są zmiennymi wbudowanymi dostęp do nich jest szybki. Ich przeznaczenie jest analogiczne do globalnych zmiennych wbudowanych.
Aktualnie w systemie docuRob®WorkFlow istnieją cztery wbudowane atrybuty tekstowe:
- attr1, attr2, attr3, attr4 – atrybuty o dowolnej interpretacji.
Dostęp do nich w dowolnej regule BPQL (w kontekście czynności) możliwy za pomocą funkcji GetActAttrValue oraz SetActAttrValue.
Reguły przepływu danych
Reguły przepływu danych są definiowane na poziomie parametrów wywoływanych aplikacji. W przypadku parametru wejściowego można określić jaka wartość zostanie podstawiona pod ten atrybut. Wyrażenie może być dowolną regułą w BPQL. Przykład takiego wyrażenia prezentuje Rysunek 7
Rysunek 7. Definiowanie wartości parametru wejściowego aplikacji
W przypadku parametrów wyjściowych można zdefiniować, do jakiej zmiennej zostanie przekazana wartość rezultatu (patrz Rysunek 8). Inne wyrażenia BPQL są tutaj niedozwolone. System nawet po wprowadzeniu innego wyrażenia BPQL dla atrybutu wyjściowego nie zgłosi błędu. Błąd ten pojawi się dopiero na etapie wykonania
Rysunek 8. Definiowanie wartości parametru wyjściowego aplikacji
Przepływ sterowania
Na podstawie przepływu określonego w modelu procesu definiujemy:
- Warunki przepływu sterowania – warunki te są reprezentowane jako reguły BPQL,
- charakterystykę przepływów czynności wskazując jak wygląda złączenie i rozdzielenie sterowania.
- akcje wykonywane przed rozpoczęciem czynności i po jej zakończeniu.
Warunki przejść
Warunki przejść są wyrażeniami logicznymi określającymi, czy dane przejście zostanie wykonane czy nie. Warunek jest reprezentowany przez regułę BPQL i może zawierać dowolne elementy języka, które ostatecznie wartościują się do typu Boolean. W praktyce warunek przepływu sterowania jest definiowany w oparciu o zmienne globalne procesu oraz funkcje BPQL, które udostępniają dane obiektów i formularzy przetwarzanych w ramach procesu.
Aby zdefiniować warunek, należy będąc na zakładce Model procesu zaznaczyć właściwe przejście i kliknąć dwukrotnie lewym klawiszem myszki. Na ekranie pojawia się okno dialogowe do wprowadzania danych o przejściu. Dostarcza ono następującej informacji:
- Od czynności – numer i nazwa czynności początkowej, od której jest zdefiniowane przejście. Wartość tylko do odczytu.
- Do czynności - numer i nazwa czynności końcowej, do której jest zdefiniowane przejście. Wartość tylko do odczytu.
- Nazwa – nazwa przejścia. Nazwa ta pojawia się w zakładce Model procesu.
- Opis – dodatkowa informacja o przejściu wypełniana w celach dokumentacyjnych.
- Warunek – wyrażenie języka BPQL.
Dla przejść można opcjonalnie pominąć nazwę przejścia a w takim przypadku zamiast nazwy zostanie na grafie Modelu procesu pokazany warunek przejścia.
Przy definiowaniu warunku przejścia możliwe jest wstawianie operatorów logicznych: AND, OR, NOT przy pomocy przycisków znajdujących się lewej dolnej części okna. W celu wybrania zmiennej globalnej lub funkcji wbudowanej BPQL, należy kliknąć na przycisk Wstaw. Na ekranie pojawia się standardowe okno wprowadzania informacji o strukturze organizacyjnej, funkcjach wbudowanych i zmiennych globalnych. Na zakładce Struktura org. można wybrać cztery kategorie danych:
- Funkcja – na ekranie pojawia się lista funkcji BPQL, które można wykorzystać do zdefiniowania warunku. Wybór funkcji następuje po dwukrotnym kliknięciu na jej nazwę lub zaznaczeniu funkcji i kliknięciu na klawisz „Wybierz”.
- Stanowisko – podaje listę stanowisk zdefiniowanych w systemie. Lista ta może się różnić w zależności od słowników danego klienta.
- Grupa – umożliwia wybranie grupy funkcyjnej lub komórki organizacyjnej zdefiniowanej w systemie docuRob®WorkFlow lub zsynchronizowanej z właściwym systemem zarządzania pracownikami.
- Pracownik- lista pracowników zatrudnionych w danej grupie lub komórce organizacyjnej wybranej z rozwijanej listy grup i komórek.
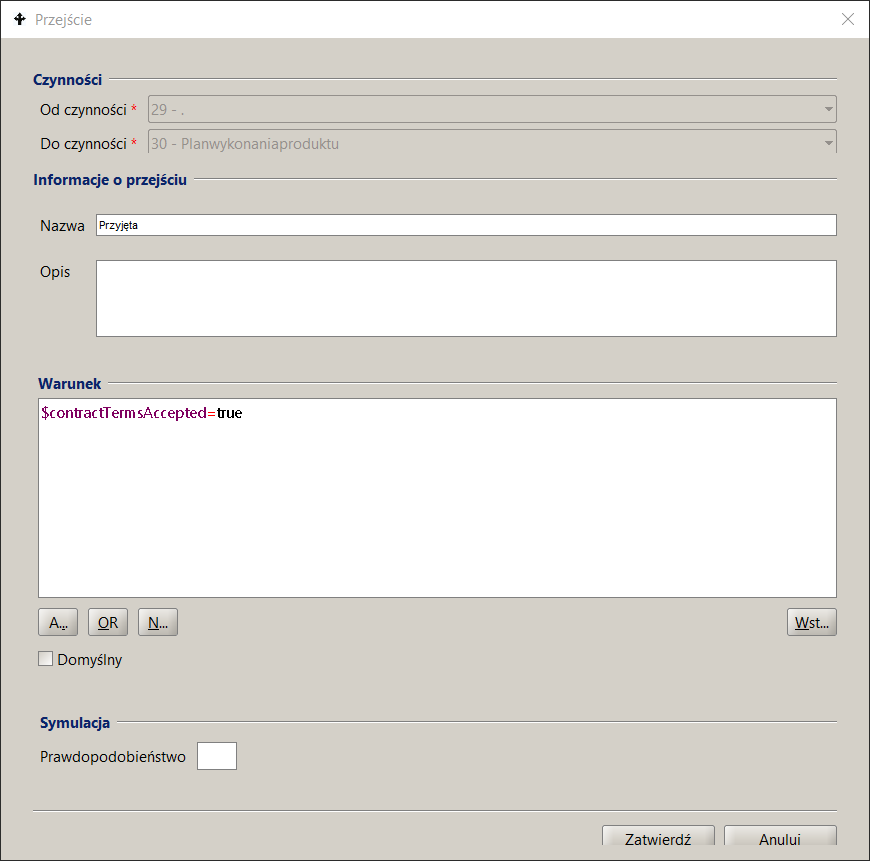
Rysunek 9. Definiowanie reguł przepływu sterowania
Wybór Funkcji BPQL oraz innych elementów dostępnych w ramach ontologii procesu prezentuje Rysunek 10.
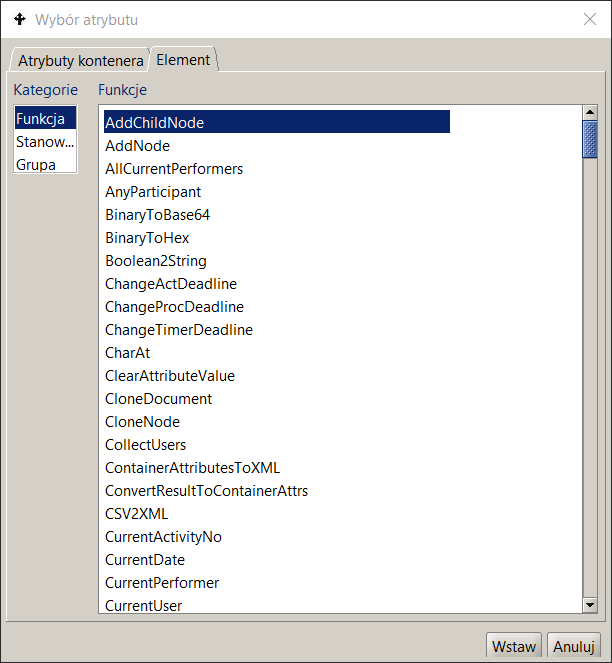
Rysunek 10. Wybór elementu wyrażenia BPQL
Wybór zmiennej globalnej (atrybutu kontenera) wykonuje się na drugiej zakładce (patrz Rysunek 11. Po jej wybraniu wyświetlana jest lista dostępnych atrybutów wraz z informacją o typie i rodzaju zmiennej. Podwójne kliknięcie na zmienną powoduje jej wybranie
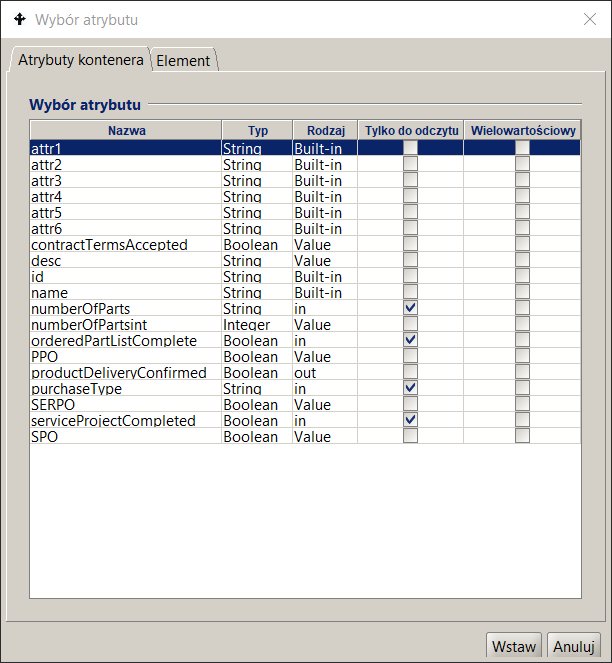
Rysunek 11. Wybór zmiennej globalnej wyrażenia BPQL
Złączenie i rozdzielenie sterowania
Złączenie i rozdzielanie sterowania wykonuje się zazwyczaj poprzez czynności sterujące. Cechy takiej czynności są uszczegóławiane już podczas modelowania procesu, w szczególności typ czynności (tj. złączenie, czy rozdzielenie sterowania, wykonywanie równoległe, opcjonalne, czy alternatywne). Podczas definicji zostaje jedynie podanie nazwy i opisu takiej czynności.
Dla każdej z czynności jest zdefiniowany sposób:
- Złączenia sterowania wykonywanego przy wejściu do tej czynności. Domyślnie jest to złączenie alternatywne (złączenie typu XOR) oznaczające, że każdy znacznik, który dotrze do czynności uruchomi ją. Inne możliwości to złączenie typu AND oraz OR. W pierwszym przypadku uruchomienie czynności nastąpi jedynie, gdy wszystkie jej wejścia będą aktywne. W drugim przypadku uruchomienie czynności nastąpi, gdy wszystkie czynności związane z tym złączeniem (tj. zawarte w ścieżkach, które zostały uruchomione przy rozdzieleniu sterowania , które jest teraz złączane) zostaną zakończone.
- Rozdzielenie sterowania wykonywane przy wyjściu z czynności. Domyślnie jest to rozłączenie opcjonalne (rozłączenie typu OR) oznaczające, że sterowanie zostanie przekazane do wszystkich przejść, dla których spełniony jest warunek przejścia. Inne możliwości to rozdzielenie typu AND oraz XOR. W pierwszym wypadku przekazanie sterowania po zakończeniu czynności nastąpi jedynie wtedy, kiedy wszystkie przejścia wychodzące z czynności są możliwe do uruchomienia. W drugim wypadku przekazanie sterowania będzie możliwe o ile tylko jedna ścieżka wychodząca będzie możliwa do realizacji (dla reszty warunki przejść nie będą spełnione).
Aby zmodyfikować przyjęty sposób złączenia/rozdzielenia sterowania, należy:
wejść we właściwości czynności. Może to być wykonane na kilka sposobów. Po pierwsze będąc w zakładce Model procesu wystarczy dwukrotnie kliknąć na danej czynności lewym klawiszem myszki. Po drugie będąc w zakładce Model procesu, na danej czynności kliknąć prawy klawisz myszki i z menu kontekstowego wybrać pozycje Właściwości. Po trzecie, będąc w zakładce Definicja procesu (panel listy definicji procesu) , rozwinąć proces i kliknąć na węźle Czynności. Następnie na prawym panelu wybrać daną czynność i kliknąć na niej dwukrotnie lewym przyciskiem myszki.
W lewym panelu okna dialogowego właściwości czynności wybrać pozycję Przepływ.
W prawym panelu należy ustawić właściwe opcje związane ze złączeniem i rozdzieleniem sterowania.
Kliknąć klawisz Zatwierdź.
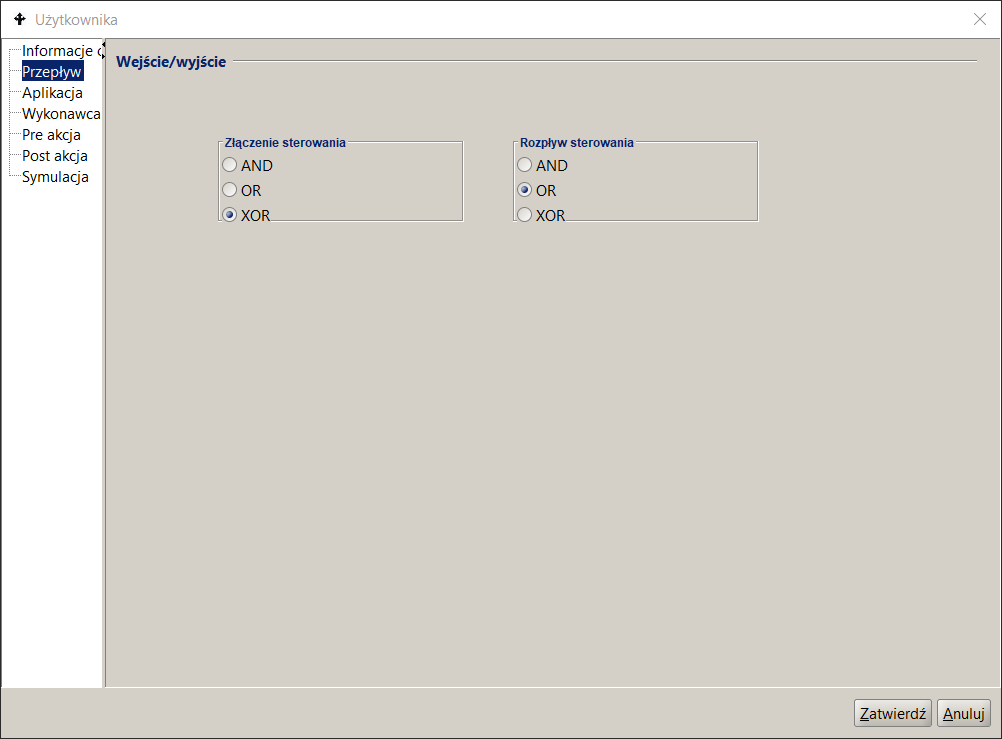
Rysunek 12. Wchodzące i wychodzące przepływy definiowane w Czynności
Wykonawcy
Kolejnym ważnym elementem definiowania czynności jest określenie wykonawcy (ów) czynności. Aby to wykonać, najpierw należy doprecyzować znaczenie ról w procesie. W następnym kroku należy wykorzystać mechanizmy wyboru i przypisania wykonawców i zdefiniować ich dla wszystkich czynności występujących w procesie.
- System docuRob®WorkFlow dostarcza trzech mechanizmów wyboru i przypisania wykonawców: reguły BPQL do wyznaczenia kandydatów na wykonawców, określenia sposobu wyboru wykonawców z listy wyznaczonych kandydatów oraz sposobu przypisania zadań do wykonawców.
- Przypisanie wykonawców jest wykonywane dwuetapowo. W trakcie przypisania wstępnego wartościowana jest reguła BPQL wyznaczająca wykonawców. W rezultacie jej wykonania otrzymywany jest zbiór potencjalnych wykonawców czynności. Zbiór ten może być jedno lub wieloelementowy (wielu wykonawców). W zależności od typu podejmowanej decyzji zbiór ten staje się automatycznie listą wykonawców czynności (decyzja „Auto”) lub podlega weryfikacji przez wybranych pracowników (decyzja Wybierz).
- Dla tak wybranych wykonawców tworzone są zadania (instancje czynności). Zadania te pojawiają się na liście zadań tych wykonawców. W zależności od ustalonej liczności, po pobraniu zadania przez dowolnego z wykonawców zadania innych wykonawców są usuwane (liczność „Jeden”) lub pozostają do wykonania (liczność „Wszyscy”). Szczegóły opisanych elementów są wyjaśniane w poniższych sekcjach.
Przypisanie wykonawców
Przypisanie wykonawców jest wyrażane przy pomocy reguły BPQL. Reguła musi jako rezultat zwracać zbiór wykonawców (tzn. typ SET<Participant>). Zbiór ten może być też jedno lub wieloelementowy.
Czynność może być wykonywana przez Osoby lub automatyczna (wykonywana przez System). W przypadku czynności automatycznej jako wykonawcę czynności należy podać:
['system']
Aby zdefiniować regułę wyboru wykonawców, należy (Rysunek 13):
- w panelu listy procesów kliknąć na dany proces,
- przejść w prawym panelu na zakładkę Model procesu. Odnaleźć właściwą czynność i kliknąć dwukrotnie. Na ekranie pojawi się okno dialogowe właściwości czynności,
- kliknąć na węźle „Wykonawca”. Wprowadzić do polu właściwą regułę BPQL.
Przy definiowaniu reguły wyboru wykonawców można wykorzystywać wbudowane funkcje BPQL, wybrane elementy struktury organizacyjnej oraz zdefiniowane zmienne globalne. Dostęp do tych elementów następuje po naciśnięciu przycisku „Wstaw”. Elementy definiowanego wyrażenia są podświetlane przy wykorzystaniu odpowiedniej kolorystyki. Inaczej oznaczana są teksty, instrukcje języka czy funkcje BPQL.
Po naciśnięciu przycisku „Zatwierdź” następuje (o ile nie odznaczono w konfiguracji narzędzia projektowania procesów opcji „Weryfikuj wyrażenia BPQL”) weryfikacja wprowadzonego wyrażenia. W przypadku identyfikacji błędów, na ekranie pojawia się stosowna informacja.
Decyzja umożliwia wykonanie ostatecznej weryfikacji listy kandydatów na wykonawców przez uprawnione osoby. Przykładem jest wyznaczenie właściwego pracownika, który zajmie się sprawą dopiero po przeanalizowaniu czego ta sprawa dotyczy. W takim wypadku system dostarcza decydentowi listę kandydatów do wykonania tej czynności a decydent, mając tak zawężoną listę, wybiera właściwego pracownika.
W systemie docuRob®WorkFlow są dostępne dwa typy decyzji:
„Auto” – system automatycznie przyjmuje, że wszyscy wyznaczeni kandydaci staja się wykonawcami tej czynności,
„Wybierz” – istnieje możliwość wyboru spośród listy kandydatów pracowników, którzy staną się wykonawcami. Ze zbioru kandydatów może zostać wybranych od jednego do N kandydatów, gdzie N jest liczbą wszystkich kandydatów.
Zaznaczanie właściwego typu decyzji jest wykonywane w oknie dialogowym wyboru Wykonawcy, w grupie „Decyzja”.
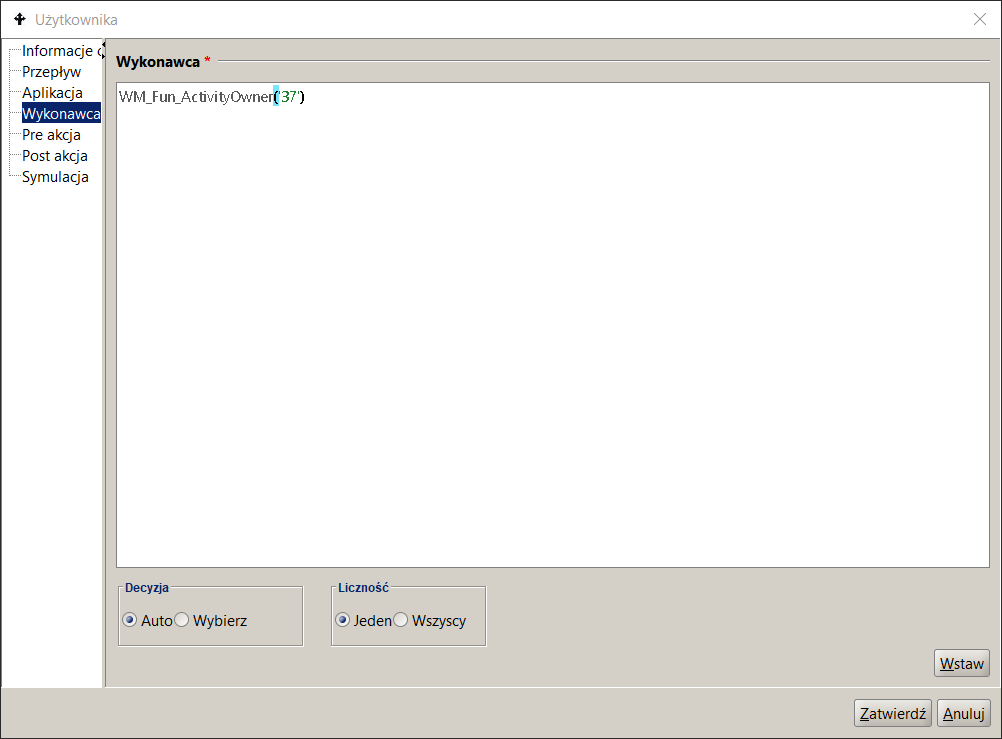
Rysunek 13. Wprowadzanie reguł przypisania Wykonawców
Liczność
Niekiedy istnieje potrzeba, aby dane zadanie zostało wykonane przez dowolnego pracownika jakiejś grupy. Jednym ze sposobów radzenia sobie w takiej sytuacji jest przydzielenie tego zadania wszystkim pracownikom tej grupy a po rozpoczęciu zadania przez jednego z nich, skasowaniu tego zadania pozostałym pracownikom.
Powyższe potrzeby są realizowane w systemie docuRob®WorkFlow przy pomocy modyfikatora Liczność. Liczność określa ilu wykonawców faktycznie wykona czynność. Aktualnie dostępne są dwie możliwości:
Jeden – czynność zostanie przypisana do wszystkich wykonawców w postaci odrębnych zadań. Po odebraniu zadania przez dowolnego z wykonawców, zadania u pozostałych wykonawców znikną (zostaną usunięte) z ich list zadań.
Wszyscy - czynność zostanie przypisana do wszystkich wykonawców w postaci odrębnych zadań. Po odebraniu zadania przez dowolnego z wykonawców, zadania u pozostałych wykonawców pozostaną na ich listach zadań
Aplikacja
Czynności wykonywane automatycznie lub przy udziale użytkownika procesu są obsługiwane poprzez wywołanie Aplikacji. Wywołanie to jest określone w ramach definiowania czynności i obejmuje specyfikację samej aplikacji oraz parametrów wejściowych i rezultatów przez nią zwracanych.
Aby zdefiniować aplikację w czynności, należy:
- w panelu listy procesów kliknąć na dany proces,
- przejść w prawym panelu na zakładkę Model procesu. Odnaleźć właściwą czynność i kliknąć dwukrotnie. Na ekranie pojawi się okno dialogowe właściwości czynności,
- kliknąć na węźle „Aplikacja”. Ekran definicji Aplikacji przedstawia Rysunek 14
- W polu „Protokół” wybrać z listy sposób komunikacji z aplikacją. Protokoły są opisane w poniższej sekcji,
- podać nazwę aplikacji oraz sposób jej realizacji nazwany usługą. W zależności od protokołu komunikacji usługa identyfikuje aplikację (wskazuje na klasę w języku Java, która reprezentuje aplikację) lub podaje jaka operacja (metoda) w ramach aplikacji będzie wykonywana,
- wyspecyfikować parametry wejściowe i wyjściowe.
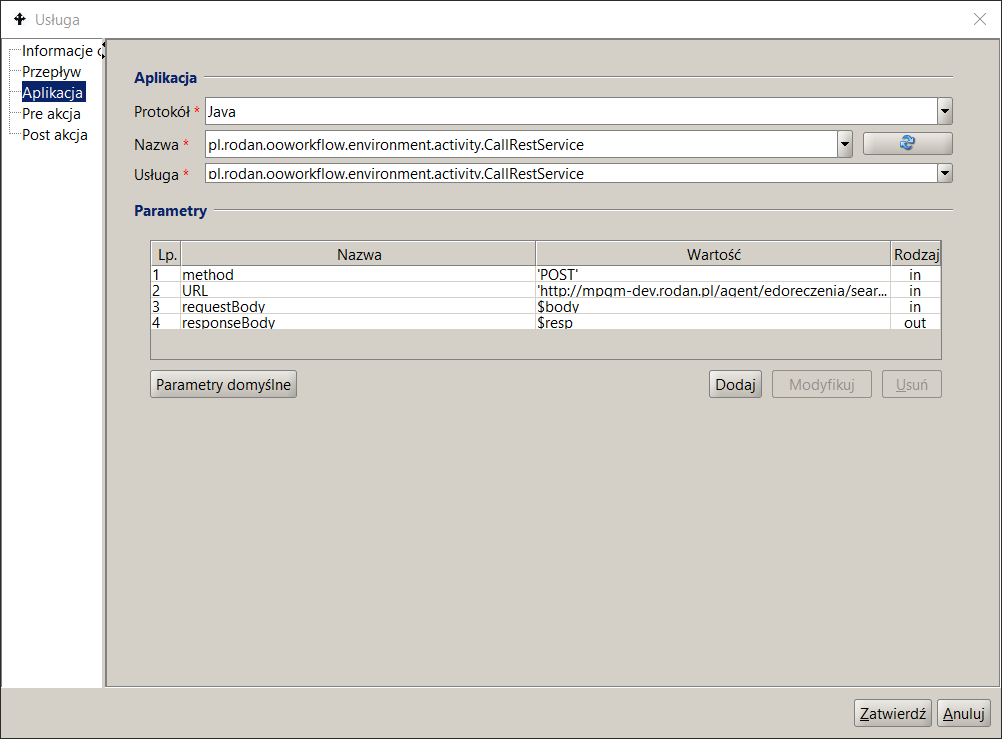
Rysunek 14. Specyfikacja wywołania Konektora usług REST
Tworzenie zadań wykorzystujących protokół REST oraz usługi sieciowe SOAP zostało przedstawione w rozdziale Czynności i przepływy procesu.
Protokół wywołania
System docuRob®WorkFlow wspiera trzy protokoły wywołania:
- Java – aplikacja implementuje interfejs aplikacji zewnętrznej zdefiniowany w systemie docuRob®WorkFlow i jest implementowana jako klasa języka Java. Protokół ten działa tylko w trybie synchronicznym. Pole usługa specyfikuje pełną lokalizację klasy (pakiety i nazwa klasy).
- URL – aplikacja jest wywoływana za pomocą adresu URL (Uniform Resource Locator,) dostępnego poprzez protokół HTTP. Protokół ten charakteryzuje przede wszystkim wywołanie czynności typu „Użytkownik”. Protokół ten działa tylko w trybie synchronicznym. Pole Usługa specyfikuje konkretny adres wywołania.
- WebService – dla usługi jest podana specyfikacji danej usługi automatycznie wczytywana jest lista parametrów wejściowych i wyjściowych. Protokół ten charakteryzuje wywołanie czynności automatycznej i działa w trybie asynchronicznym. Pole „Nazwa” określa nazwę usługi a pole „Usługa” specyfikuje nazwę wywoływanej operacji w tej usłudze.
Usługa sieciowa
Rysunek 15 przedstawia przykład wywołania usługi sieciowej w oparciu o protokół SOAP.
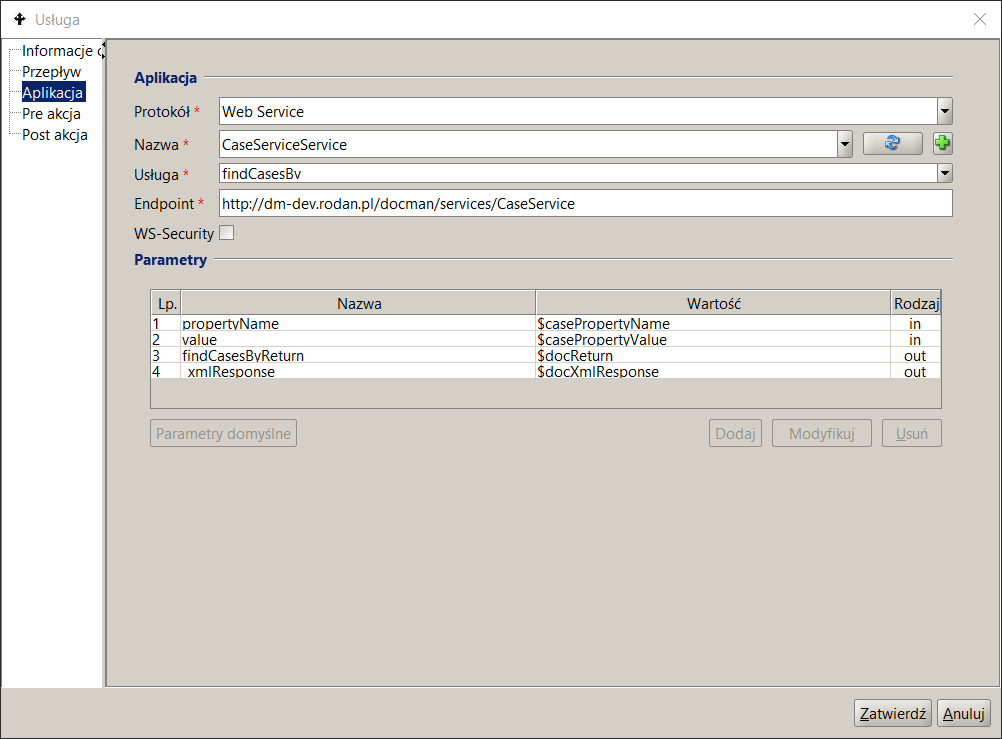
Rysunek 15. Specyfikacja wywołania usługi sieciowej SOAP
Przypisanie parametrów wejściowych i rezultatów
Definiowanie parametrów wejściowych i rezultatów jest wykonywane poprzez kliknięcie klawisza „Dodaj”. Na ekranie pojawia się okno, w którym należy podać (patrz Rysunek 14):
typ parametru - parametr może być wejściowy lub wyjściowy.
nazwę parametru - jeżeli specyfikacja aplikacji była odczytana automatycznie, to nazwa parametru jest już wprowadzona.
wartość parametru W przypadku parametru wejściowego może to być dowolne wyrażenie w BPQL o typie zgodnym z typem parametru. W przypadku parametru wyjściowego musi to być nazwa zmiennej globalnej lub parametru wyjściowego procesu, na który zostanie przepisana zwrócona wartość.
Podproces
W czynności złożonej wywoływany jest inny proces traktowany jako Podproces. Wywołanie to jest wykonywane w trybie synchronicznym. Wywoływany Proces traktuje się jak aplikację i przy definicji czynności złożonej należy określić mapowania na parametry wejściowe i wyjściowe Podprocesu.
Aby w czynności złożonej określić wołany Podproces, należy:
- w panelu listy procesów kliknąć na dany proces,
- przejść w prawym panelu na zakładkę Model procesu. Odnaleźć właściwą czynność i kliknąć dwukrotnie. Na ekranie pojawi się okno dialogowe właściwości czynności,
- kliknąć na węźle Proces.
- W polu Nazwa wybrać odpowiedni proces (patrz Rysunek 16). Po wybraniu procesu system docuRob®WorkFlow automatycznie przepisze listę parametrów wejściowych i wyjściowych wybranego podprocesu.
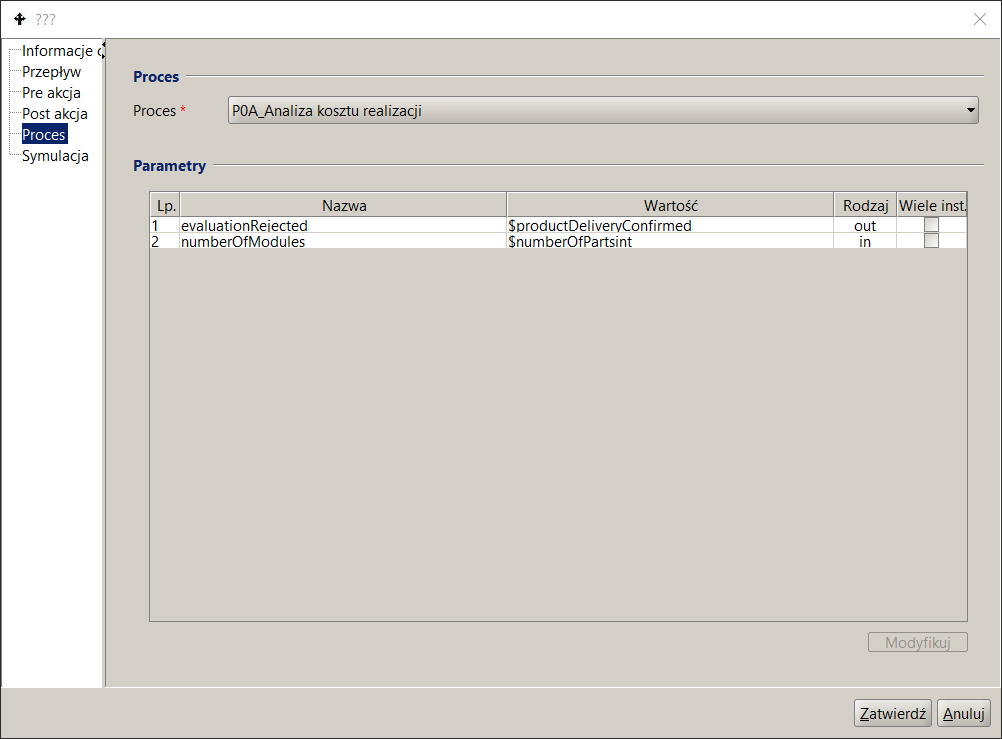
Rysunek 16. Specyfikacja wołania Podprocesu
Ograniczenia czasowe
System docuRob®WorkFlow wspiera definiowanie ograniczeń czasowych na poziomie procesu oraz poszczególnych czynności. Na poziomie procesu możliwe jest definiowanie maksymalnego czasu realizacji procesu. Czas ten jest wyrażany w dniach i godzinach. Dla danej instancji czas ten jest liczony od momentu uruchomienia procesu. Przekroczenie zdefiniowanego czasu powoduje, że cały proces (instancja procesu) jest opóźniona. Dodatkowo możliwe jest też zdefiniowanie reguły wyboru pracowników, którzy powinni zostać powiadomieni w przypadku zaistniałego opóźnienia. Reguła ta ma te same ograniczenia co reguły wyboru wykonawców w czynnościach.
Aby zdefiniować ograniczenie na poziomie procesu, należy:
- W panelu listy procesów kliknąć na dany proces.
- W prawym panelu kliknąć na dolnej zakładce Informacja o realizacji procesu.
- Wprowadzić właściwe wartości w pola dni i godzin.
- Wprowadzić regułę BPQL wyznaczającą pracowników, którzy zostaną powiadomieni w przypadku zaistnienia opóźnienia.
Ograniczenia można określić na dwa sposoby:
- W postaci dni i godzin.
- W postaci procentu maksymalnego czasu realizacji procesu.
Jeżeli w czasie wykonywania procesu nastąpi niedotrzymanie tych ograniczeń, to:
- Czynność będzie opóźniona.
- W zależności, czy czynność ta leży na ścieżce krytycznej, cały proces będzie opóźniony.
Jeżeli czynność jest wykonywana wielokrotnie w pętli, to liczenie czasów rozpoczyna się na pierwszym uruchomieniu tej czynności a kończy na ostatnim uruchomieniu.
Określenie właściciela instancji procesu
Właściciel wykonywanego procesu (instancji procesu) powinien być określony już na etapie identyfikacji procesu. Z drugiej strony jego właściwą definicję można podać bardzo często dopiero po przygotowaniu pełnej definicji procesu. Definicja właściciela procesu jest reprezentowana poprzez regułę BPQL tak jak dla reguł wyboru wykonawcy.
Aby uniknąć problemów z niewłaściwym przypisaniem właściciela procesu, należy wyrażenie wyboru właściciela maksymalnie uprościć. Najlepiej, jeżeli jest to możliwe, należy podać właściciela procesu z nazwiska i imienia - tego samego dla wszystkich instancji.
Aby zdefiniować właściciela procesu, należy:
- W panelu listy procesów kliknąć na dany proces.
- W prawym panelu rozwinąć pole „Właściciel instancji**”**.
- Zdefiniować regułę BPQL określania właściciela procesu.